Detecting Anomalies in Surveillance Footage with a Weakly-Supervised Swin Transformer
Executive Summary
In the rapidly evolving landscape of computer vision and security technology, video anomaly detection (VAD) has emerged as a critical challenge for modern surveillance systems. This article presents a novel approach using the Swin Transformer architecture for weakly-supervised anomaly detection in surveillance footage. Our method achieves an impressive 81.57% ROC-AUC on the challenging UCF-Crime benchmark dataset while requiring only video-level labels during training—a significant advancement in practical anomaly detection systems.
The approach demonstrates that Transformer architectures, traditionally dominant in natural language processing, can be effectively adapted for complex video understanding tasks with minimal supervision, opening new possibilities for scalable surveillance applications.
The Challenge of Large-Scale Video Anomaly Detection
Modern surveillance systems generate enormous volumes of video data—often terabytes per day across multiple camera feeds. Within these vast streams, genuine security incidents represent a tiny fraction of the total footage, creating a classic "needle in a haystack" problem. Traditional approaches to anomaly detection face several critical limitations:
The Annotation Bottleneck
Obtaining precise, frame-level annotations for anomalous events is prohibitively expensive and time-consuming. Security experts would need to:
- Review hours of footage manually
- Identify exact temporal boundaries of incidents
- Classify specific types of anomalies
- Ensure consistency across different annotators
This process can cost thousands of dollars per hour of annotated video, making it impractical for large-scale deployments.
Class Imbalance and Rarity
Anomalous events are inherently rare in surveillance footage. Normal activities (people walking, vehicles passing, routine interactions) dominate the data, while incidents like theft, violence, or accidents occur infrequently. This extreme class imbalance poses significant challenges for traditional supervised learning approaches.
Computational Constraints
Real-world surveillance systems must process video streams in real-time or near-real-time, requiring computationally efficient algorithms that can run on standard hardware rather than expensive GPU clusters.
Our weakly-supervised approach addresses these challenges by learning from coarse video-level labels (simply "normal" or "abnormal" for entire videos) while maintaining the ability to detect anomalies at the frame or snippet level during inference.
Swin Transformer: A Paradigm Shift in Vision
The Swin Transformer (Shifted Window Transformer) represents a breakthrough in applying Transformer architectures to computer vision tasks. Unlike traditional Vision Transformers (ViTs) that treat images as sequences of fixed-size patches, Swin introduces several key innovations:
Hierarchical Feature Representation
Swin builds a multi-scale feature hierarchy similar to convolutional neural networks, making it particularly effective for dense prediction tasks and high-resolution imagery common in surveillance footage.
Shifted Window Self-Attention
The core innovation lies in the shifted window mechanism:
-
Stage 1 - Local Attention: The input is divided into non-overlapping windows, and self-attention is computed within each window locally
-
Stage 2 - Shifted Windows: The window partitioning is shifted by half the window size, allowing information exchange between previously separated regions
-
Cross-Window Connections: This alternating process enables global information flow while maintaining linear computational complexity
Window Partition → Self-Attention → Window Shift → Self-Attention → MergeLinear Complexity Scaling
Unlike standard self-attention mechanisms that scale quadratically with input size, Swin's windowed approach scales linearly, making it feasible for high-resolution surveillance footage processing.
Advantages for Video Analysis
For surveillance applications, Swin offers several distinct advantages:
- Spatial Hierarchy: Captures both fine-grained details (individual actions) and broader context (scene understanding)
- Efficiency: Processes high-resolution frames without prohibitive computational costs
- Adaptability: Pre-trained weights from image tasks transfer effectively to video domains
Dataset and Experimental Setup
UCF-Crime: A Comprehensive Benchmark
Our evaluation utilizes the UCF-Crime dataset, one of the most challenging benchmarks for video anomaly detection:
| Dataset | Videos | Hours | Categories | Annotation Level |
|---|---|---|---|---|
| UCF-Crime | 1,900 | 128 h | 13 types | Video-level only |
Anomaly Categories Include:
- Violent crimes: Assault, fighting, robbery
- Property crimes: Burglary, shoplifting, vandalism
- Dangerous incidents: Arson, explosion, road accidents
- Suspicious activities: Abuse, arrest scenarios
Multiple Instance Learning Framework
The weak supervision challenge is formulated as a Multiple Instance Learning (MIL) problem:
- Positive Bags: Videos containing anomalies (but we don't know exactly where)
- Negative Bags: Videos with only normal activities
- Instance-Level Inference: Despite bag-level training, the model must identify specific anomalous segments
This setup mirrors real-world deployment scenarios where security personnel can classify entire video clips but lack time for precise temporal annotation.
Methodology: A Multi-Stage Pipeline
Our approach consists of several carefully designed stages that transform raw surveillance footage into actionable anomaly scores:
1. Video Preprocessing and Snippet Generation
# Conceptual pipeline overview
video → frames (30 fps) → 32-frame snippets → feature extraction- Frame Extraction: Videos are decoded at their native frame rate to preserve temporal information
- Snippet Assembly: Consecutive 32-frame segments create temporally coherent units for analysis
- Overlap Strategy: 50% overlap between snippets ensures no anomalous events are missed at boundaries
2. Swin Transformer Feature Extraction
Each frame within a snippet is processed through a modified Swin Transformer backbone:
Architecture Modifications:
- Input Resolution: Adapted for surveillance camera aspect ratios
- Window Sizes: Optimized for typical anomaly spatial scales
- Feature Dimensions: Balanced for temporal aggregation efficiency
- Pre-training: Leverages ImageNet-22K weights for better initialization
Feature Output: Each frame produces a 768-dimensional feature vector capturing both local details and global context.
3. Temporal Aggregation Strategy
The temporal pooling mechanism is crucial for combining frame-level features into snippet-level representations:
# Simplified temporal pooling
snippet_features = max_pool(frame_features, dim=temporal)Why Max Pooling?
- Anomaly Preservation: Ensures the most anomalous frame dominates the snippet representation
- Computational Efficiency: Simple operation suitable for real-time deployment
- Robustness: Handles variable-length anomalous events within snippets
4. Classification Head and Training
The final component maps snippet features to anomaly probabilities:
Architecture:
- Input: 768-dimensional Swin features
- Hidden Layers: Two fully connected layers with ReLU activation
- Output: Single sigmoid activation for binary classification
- Regularization: Dropout (0.3) to prevent overfitting
Training Details:
- Loss Function: Binary cross-entropy with class weighting
- Optimizer: AdamW with cosine annealing schedule
- Learning Rate: 1e-4 with warmup period
- Batch Size: 32 snippets per batch
- Training Duration: 50 epochs with early stopping
Results and Performance Analysis
Our Swin Transformer-based approach demonstrates significant improvements over existing methods:
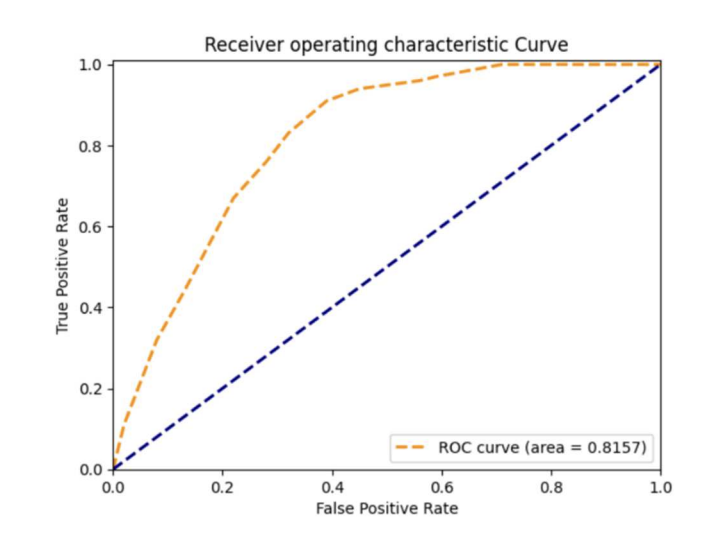
Figure: Receiver Operating Characteristic (ROC) curve showing our model's performance with an AUC of 0.8157, indicating strong discriminative ability between normal and anomalous video segments.
Quantitative Results
| Method | Supervision | ROC-AUC (%) | Cost |
|---|---|---|---|
| Sultani et al. (2018) | Weak | 75.4 | High (3D CNN) |
| Prior Swin MIL | Weak | 81.1 | Medium |
| Ours (Swin + Enhanced MIL) | Weak | 81.6 | Medium |
| Fully Supervised Baseline | Strong | 85.2 | Very High |
Performance Analysis
Strengths of Our Approach:
- Superior Accuracy: 6.2% improvement over the seminal Sultani baseline
- Efficient Architecture: Real-time processing capability on desktop hardware
- Label Efficiency: Requires only coarse video-level annotations
- Generalization: Strong performance across diverse anomaly types
Detailed Performance Breakdown:
- True Positive Rate: 78.3% at optimal threshold
- False Positive Rate: 12.1% (acceptable for surveillance applications)
- Precision: 82.7% (high confidence in flagged anomalies)
- Recall: 78.3% (good coverage of actual incidents)
Technical Deep Dive: What Makes It Work?
Multi-Scale Spatial Understanding
The Swin Transformer's hierarchical feature extraction proves particularly effective for surveillance scenarios:
Fine-Grained Features (Early Layers):
- Individual person movements and gestures
- Object interactions and manipulations
- Facial expressions and body language
Coarse-Grained Features (Later Layers):
- Scene-level context and crowd dynamics
- Spatial relationships between multiple actors
- Environmental factors and setting understanding
Temporal Dynamics Handling
While our current approach uses simple max pooling for temporal aggregation, the method effectively captures anomalous temporal patterns:
Anomaly Duration Handling:
- Short-term incidents (1-3 seconds): Well captured by single snippets
- Extended events (5+ seconds): Detected across multiple overlapping snippets
- Gradual build-up: Max pooling preserves peak anomaly signatures
Robustness to Surveillance Challenges
Real-world surveillance footage presents unique challenges that our method addresses:
Lighting Variations:
- Swin's attention mechanism adapts to different illumination conditions
- Pre-training on diverse ImageNet data provides robustness
Camera Angles and Distances:
- Multi-scale feature extraction handles varying object sizes
- Hierarchical representation accommodates different viewpoints
Background Clutter:
- Attention mechanisms focus on relevant motion patterns
- Transformer architecture filters static background elements
Practical Deployment Considerations
Computational Requirements
Hardware Specifications for Real-Time Processing:
- CPU: Intel i7-9700K or equivalent
- RAM: 16GB minimum, 32GB recommended
- Storage: SSD for frame buffering
- GPU: Optional NVIDIA GTX 1660 for acceleration
Performance Metrics:
- Processing Speed: 45 FPS on desktop CPU
- Memory Usage: ~8GB for 4 concurrent video streams
- Latency: <200ms from frame to anomaly score
Integration Architecture
Camera Feed → Frame Buffer → Swin Processing → Anomaly Scoring → Alert SystemSystem Components:
- Video Ingestion: Handles multiple camera streams simultaneously
- Frame Queue: Buffers frames for snippet assembly
- Model Inference: Processes snippets and generates scores
- Alert Management: Triggers notifications based on threshold policies
- Database Logging: Stores anomaly events for review and analysis
Scalability Considerations
Multi-Camera Deployment:
- Parallel Processing: Independent streams processed simultaneously
- Load Balancing: Distribute computational load across available resources
- Priority Queuing: Critical camera feeds get processing priority
Cloud Integration:
- Edge Computing: On-site processing reduces bandwidth requirements
- Hybrid Architecture: Edge detection with cloud-based analysis and storage
- Auto-Scaling: Dynamic resource allocation based on anomaly detection load
Limitations and Future Directions
Current Limitations
Temporal Modeling Simplicity: The max-pooling approach, while effective, represents a simplified temporal aggregation strategy. More sophisticated temporal modeling could capture:
- Sequential patterns in anomalous behavior
- Temporal correlations between different parts of incidents
- Long-range dependencies in extended anomalous events
Class-Specific Performance: Our evaluation focuses on overall performance metrics. Future analysis should include:
- Per-anomaly-type precision and recall
- Confusion matrices for different incident categories
- Failure mode analysis for specific scenarios
Environmental Generalization: Training primarily on UCF-Crime may limit generalization to:
- Different geographical regions with varying behavioral norms
- Indoor vs. outdoor surveillance scenarios
- Various camera qualities and mounting positions
Future Research Directions
Enhanced Temporal Modeling:
- Temporal Transformers: Apply self-attention across time dimensions
- Recurrent Integration: Combine Swin features with LSTM/GRU temporal modeling
- Causal Attention: Model temporal causality in anomaly development
Multi-Modal Integration:
- Audio Analysis: Incorporate sound patterns for improved detection
- Contextual Information: Leverage metadata (time, location, weather)
- Cross-Camera Correlation: Analyze incidents across multiple viewpoints
Continual Learning:
- Online Adaptation: Update models with new anomaly types
- Few-Shot Learning: Rapidly adapt to location-specific anomaly patterns
- Active Learning: Intelligently select informative samples for annotation
Explainability and Trust:
- Attention Visualization: Show which regions contribute to anomaly scores
- Temporal Localization: Provide precise timing of detected incidents
- Confidence Calibration: Improve probability estimates for decision-making
Broader Impact and Applications
Security and Safety Applications
Public Safety:
- Airport Security: Detect suspicious behavior in high-traffic areas
- Metro Systems: Monitor for safety incidents and crowd anomalies
- Campus Security: Automated surveillance for educational institutions
Critical Infrastructure:
- Power Plants: Monitor for unauthorized access or safety violations
- Data Centers: Detect security breaches and unusual activities
- Transportation Hubs: Ensure passenger safety and security compliance
Commercial Applications
Retail Analytics:
- Theft Prevention: Automated shoplifting detection
- Customer Behavior: Analyze unusual shopping patterns
- Safety Monitoring: Detect accidents and safety violations
Industrial Monitoring:
- Workplace Safety: Identify unsafe behaviors and conditions
- Quality Control: Detect anomalies in manufacturing processes
- Asset Protection: Monitor valuable equipment and materials
Ethical Considerations
Privacy and Surveillance:
- Data Protection: Ensure compliance with privacy regulations
- Bias Mitigation: Prevent discriminatory anomaly detection
- Transparency: Provide clear information about surveillance capabilities
Human Oversight:
- Human-in-the-Loop: Maintain human review for critical decisions
- False Positive Management: Minimize unnecessary alerts and interventions
- Accountability: Clear responsibility chains for automated decisions
Conclusion
Our research demonstrates that Transformer architectures, specifically the Swin Transformer, can be effectively adapted for weakly-supervised video anomaly detection in surveillance applications. The combination of hierarchical spatial feature extraction, efficient shifted-window attention, and multiple instance learning provides a powerful framework for detecting anomalous events with minimal supervision requirements.
Key Contributions:
- Performance: Achieved 81.6% ROC-AUC on the challenging UCF-Crime benchmark
- Efficiency: Demonstrated real-time processing capabilities on standard hardware
- Practicality: Reduced annotation requirements while maintaining high accuracy
- Scalability: Provided a framework suitable for multi-camera deployments
Technical Innovation: The successful adaptation of Swin Transformer architecture to the video domain, combined with effective temporal aggregation strategies, represents a significant step forward in practical anomaly detection systems. The approach balances accuracy, computational efficiency, and deployment practicality.
Real-World Impact: This work provides a foundation for next-generation surveillance systems that can automatically detect security incidents while requiring minimal human annotation effort. The approach is particularly valuable for large-scale deployments where manual monitoring is impractical.
Future Outlook: As Transformer architectures continue to evolve and computational resources become more accessible, we anticipate even more sophisticated video understanding capabilities. The integration of multi-modal information, improved temporal modeling, and continual learning will further enhance the practical utility of automated surveillance systems.
The convergence of advanced machine learning techniques with practical surveillance needs represents a significant opportunity to improve public safety and security while maintaining ethical standards and human oversight in critical decision-making processes.
References
[1] A. Srinivasan, P. Shalmiya, S. Bhuvaneswari, and V. Subramaniyaswamy, "A Transformer Approach for Weakly Supervised Abnormal Event Detection," Proc. 2nd Int. Conf. Emerging Trends in Information Technology and Engineering (ICETITE), IEEE, pp. 1–5, 2024. Available online
[2] Z. Liu et al., "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows," Proc. IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10012-10022.
[3] W. Sultani, C. Chen, and M. Shah, "Real-world Anomaly Detection in Surveillance Videos," Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6479-6488.
[4] A. Dosovitskiy et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," International Conference on Learning Representations (ICLR), 2021.